概述
ScheduledThreadPoolExecutor提供了在给定的延迟时间之后或者以固定的速率执行任务的机制,也就是我们平时所说的任务调度。ScheduledThreadPoolExecutor本身是继承了ThreadPoolExecutor,与ThreadPoolExecutor不同的是它屏蔽了对maximumPoolSize的支持,仅仅使用corePoolSize作为固定大小线程池,其内部是通过一个以数组实现的最小堆无界队列来保存那些被调度的任务,执行这些任务的线程只能是核心线程,也就是说当我们有2个耗时为2秒的周期任务需要每隔2s需要执行一次的话,如果核心线程数为1,那么其中一个任务必须等待另外一个任务执行完毕才有可能执行。
例子
在文章的开头我们先通过一个简单的例子来了解一下如何使用ScheduledThreadPoolExecutor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| package com.example.demo;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.LockSupport;
@Slf4j
public class ScheduledThreadPoolExecutorDemo {
private static ScheduledThreadPoolExecutor scheduledThreadPoolExecutor = new ScheduledThreadPoolExecutor(4);
private static ExecutorService threadPoolExecutor = Executors.newFixedThreadPool(4);
public static void main(String[] args) {
threadPoolExecutor.execute(ScheduledThreadPoolExecutorDemo::delayRunnable);
threadPoolExecutor.execute(ScheduledThreadPoolExecutorDemo::delayCallable);
threadPoolExecutor.execute(ScheduledThreadPoolExecutorDemo::fixedRateRunnable);
threadPoolExecutor.execute(ScheduledThreadPoolExecutorDemo::fixedDelayRunnable);
}
@SneakyThrows
private static void delayRunnable() {
scheduledThreadPoolExecutor.schedule(() -> {
log.info("延迟2秒的Runnable任务开始执行");
LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(2));
log.info("延迟2秒的Runnable任务执行完毕");
}, 2, TimeUnit.SECONDS);
}
@SneakyThrows
private static void delayCallable() {
scheduledThreadPoolExecutor.schedule(() -> {
log.info("延迟2秒的Callable任务开始执行");
LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(2));
log.info("延迟2秒的Callable任务执行完毕");
return null;
}, 2, TimeUnit.SECONDS);
}
@SneakyThrows
private static void fixedDelayRunnable() {
scheduledThreadPoolExecutor.scheduleWithFixedDelay(() -> {
log.info("固定delay为2秒的Runnable任务开始执行");
LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(4));
log.info("固定delay为2秒的Runnable任务执行完毕");
}, 1, 2, TimeUnit.SECONDS).get();
}
@SneakyThrows
private static void fixedRateRunnable() {
AtomicInteger i = new AtomicInteger();
scheduledThreadPoolExecutor.scheduleAtFixedRate(() -> {
i.getAndIncrement();
if (i.get() == 4) {
throw new RuntimeException();
}
log.info("固定Rate为2秒的Runnable任务开始执行");
LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(1));
log.info("固定Rate为2秒的Runnable任务执行完毕");
}, 1, 2, TimeUnit.SECONDS).get();
}
}
|
上面的例子分别通过delayRunnable、delayCallable、fixedDelayRunnable、fixedRateRunnable这四个方法来演示了如何通过ScheduledThreadPoolExecutor来对任务进行调度,大家可以将上面的代码拷贝下来观察一下控制台的输出,理解一下这四个方法对应的调度机制。下面我们将深入研究这些调度方法背后实现的原理。
调度方法
ScheduledThreadPoolExecutor实现了ScheduledExecutorService接口定义的一些调度方法,我们平时使用ScheduledThreadPoolExecutor时基本上就是通过这些方法来对任务进行调度的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| package java.util.concurrent;
public interface ScheduledExecutorService extends ExecutorService {
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay, TimeUnit unit);
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
}
|
下面我们对这些方法的含义解释一下
schedule(Runnable command,long delay, TimeUnit unit);
这个方法的作用是在指定的delay之后执行command任务,这是一个一次性操作,command只会被执行一次
schedule(Callable callable, long delay, TimeUnit unit);
与第一个调度方法作用相似,不同之处在于执行的是一个Callable
scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);
这个方法的作用是在给定的initialDelay之后开始执行command任务,然后以固定的频率period周期性的执行这个任务。需要注意的是如果任务本身执行时长超过了period,那么就会等待任务执行完毕后立马执行该任务而不会让另一个核心线程并发执行这个任务。
scheduleWithFixedDelay(Runnable command,long initialDelay,long delay, TimeUnit unit);
这个方法的作用是在给定的initialDelay之后开始执行command任务,然后在一次任务的终止与下一次开始之间以固定的delay循环执行,说白了就是每次任务执行完毕之后会等待delay之后再次执行。
在ScheduledExecutorService定义的调度方法中我们可以看到每个调度方法返回的都是ScheduledFuture对象,顾名思义这是一个调度任务对象。下面我们就来看一下这个ScheduledFuture对象是什么。
调度任务
执行完调度方法后会返回一个调度任务对象,而这个调度任务对象则是以ScheduledFuture的方式所定义。
1
2
| public interface ScheduledFuture<V> extends Delayed, Future<V> {
}
|
ScheduledFuture继承了Delayed和Future接口,Future接口在之前的文章中我们知道它提供了一些对任务的取消、任务结果获取以及任务状态等判断的定义,而Delayed这个接口从名字上我们大概也能猜到它应该是提供一些对任务延迟属性的定义。
Delayed
1
2
3
4
5
| package java.util.concurrent;
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
|
Delayed接口的定义很简单,仅仅定义了一个以给定的时间单位获取任务剩余延迟的方法。即任务还剩多久时间就可以开始执行了。同时Delayed接口也继承了Comparable接口代表两个延迟对象是能够比较的,不难猜出剩多时间多的任务一般是比剩余时间少的任务大的。(即晚执行)
ScheduledThreadPoolExecutor
在知道了有哪些调度方法以及调度方法返回的调度任务对象之后,我们心里面已经对ScheduledThreadPoolExecutor的执行机制有了一个初步的了解,下面我们就来看一下ScheduledThreadPoolExecutor内部实现这些调度任务的逻辑,首先我们先看一下它的几个构造器。
构造器
ScheduledThreadPoolExecutor一共定义了四个构造器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
|
从上面的构造器参数我们可以发现,最终的ScheduledThreadPoolExecutor对象的maximumPoolSize值都是Integer.MAX_VALUE,BlockingQueue都是一个DelayedWorkQueue。对ThreadPoolExecutor内部原理了解的同学都知道只有当阻塞队列任务已满的情况下线程池才会去创建一个新的线程直到超过maximumPoolSize然后执行拒绝策略,而在文章的开头处我提到了ScheduledThreadPoolExecutor内部是通过一个最小堆无界队列来保存任务的,所以任务队列是永远不会满的,线程池中存活的只有核心线程,从侧面告诉我们执行调度任务的线程就是核心线程。能够同时执行调度任务的数量取决于核心线程数。
重写的execute和submit方法
execute和submit方法是ExecutorService和Executor接口定义的执行提交任务的方法,ThreadPoolExecutor已经实现了这些方法,而ScheduledThreadPoolExecutor内部又重写了这些方法,下面我们看一下其内部重写的逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public void execute(Runnable command) {
schedule(command, 0, NANOSECONDS);
}
public Future<?> submit(Runnable task) {
return schedule(task, 0, NANOSECONDS);
}
public <T> Future<T> submit(Runnable task, T result) {
return schedule(Executors.callable(task, result), 0, NANOSECONDS);
}
public <T> Future<T> submit(Callable<T> task) {
return schedule(task, 0, NANOSECONDS);
}
|
可以发现,execute和submit方法都调用了ScheduledExecutorService中两个一次性的调度方法,也就是说通过ScheduledThreadPoolExecutor方法执行execute和submit方法的结果就相当于在延迟0秒后执行这个任务。下面我们就来看一下ScheduledThreadPoolExecutor内部对这些调度方法的具体实现。
调度方法的实现
在开始分析调度方法的实现前我们需要先了解一下上面我们提到的调度任务ScheduledFuture的实现,在ScheduledThreadPoolExecutor内部有一个名为ScheduledFutureTask的类定义如下:
ScheduledFutureTask
1
2
3
| private class ScheduledFutureTask<V> extends FutureTask<V> implements RunnableScheduledFuture<V> {
......
}
|
ScheduledFutureTask继承了FutureTask实现了RunnableScheduledFuture接口,不了解FutureTask的同学可以看我之前写的文章。这个RunnableScheduledFuture是什么东西呢?
1
2
3
4
| public interface RunnableScheduledFuture<V> extends RunnableFuture<V>, ScheduledFuture<V> {
boolean isPeriodic();
}
|
RunnableScheduledFuture接口继承了RunnableFuture接口使自身成为了一个Runnable对象,同时也继承了ScheduledFuture对象使自身成为了一个能够调度的任务对象。内部仅仅定义了一个isPeriodic方法,判断任务本身是否是一个周期性任务。
我不是很明白这个接口的意义,为什么不直接让ScheduledFuture继承Runnable然后将这个方法定义在ScheduledFuture内部呢?
现在我们知道内部类ScheduledFutureTask是一个继承FutureTask的能够运行的Runnable,同时本身也是一个延迟对象,能够通过Delayed的getDelay方法来获取剩余执行的时间和RunnableScheduledFuture的isPeriodic方法来表明自身是否是一个周期任务。下面我们详细看一下这个ScheduledFutureTask类内部的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
| private class ScheduledFutureTask<V>
extends FutureTask<V> implements RunnableScheduledFuture<V> {
private final long sequenceNumber;
private long time;
private final long period;
RunnableScheduledFuture<V> outerTask = this;
int heapIndex;
ScheduledFutureTask(Runnable r, V result, long ns) {
super(r, result);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask(Callable<V> callable, long ns) {
super(callable);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), NANOSECONDS);
}
public int compareTo(Delayed other) {
if (other == this)
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
public boolean isPeriodic() {
return period != 0;
}
private void setNextRunTime() {
long p = period;
if (p > 0)
time += p;
else
time = triggerTime(-p);
}
public boolean cancel(boolean mayInterruptIfRunning) {
boolean cancelled = super.cancel(mayInterruptIfRunning);
if (cancelled && removeOnCancel && heapIndex >= 0)
remove(this);
return cancelled;
}
public void run() {
boolean periodic = isPeriodic();
if (!canRunInCurrentRunState(periodic))
cancel(false);
else if (!periodic)
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}
}
|
在熟悉了调度任务的具体实现之后,接下来我们再来看一下ScheduledThreadPoolExecutor是如何将Runnable进行调度的。
任务调度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(-delay));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
|
在上面的四个调度实现中我们发现其内部的实现大体一致主要分为如下几个步骤
- 对任务和时间单位的null判断,都周期任务delay值>0判断
- 通过triggerTime方法计算任务首次执行的时间,然后构造成ScheduledFutureTask任务对象
- 调用钩子decorateTask方法以便用户能够对任务进行修改和替换
- 调用delayedExecute方法对任务的执行进行一些提前的操作
triggerTime
1
2
3
| private long triggerTime(long delay, TimeUnit unit) {
return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
}
|
将延迟执行的时间转换为纳秒然后调用triggerTime方法计算任务下次执行的具体时间
1
2
3
4
| long triggerTime(long delay) {
return now() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
|
任务下次执行的时间为当前时间加上入参delay,这里对用户传递的参数delay进行了一个溢出操作的判断,如果传递的参数超过了Long.MAX_VALUE / 2的话则调用overflowFree方法矫正延迟时间。(为什么是Long最大值的一半?)
overflowFree
1
2
3
4
5
6
7
8
9
| private long overflowFree(long delay) {
Delayed head = (Delayed) super.getQueue().peek();
if (head != null) {
long headDelay = head.getDelay(NANOSECONDS);
if (headDelay < 0 && (delay - headDelay < 0))
delay = Long.MAX_VALUE + headDelay;
}
return delay;
}
|
说实话我也没看懂这个方法的的意图,不过作者在方法注释上面写道:将队列中所有延迟的值限制在Long.MAX_VALUE之内,以避免compareTo中溢出。 当添加某些延迟为Long.MAX_VALUE的任务时,如果任务有资格出队,但尚未出队,则可能会发生这种情况。
意思是如果线程池中没有空闲的线程时,此刻往线程池中提交一个延迟时间为Long.MAX_VALUE的任务时,在任务入队时进行compareTo方法比较会产生溢出。我还是不能完全理解这段话的意思,有理解的同学麻烦留言告诉我一下。
计算出任务延迟执行的时间后,接下来则是调用delayedExecute方法对任务的执行进行一些提前的操作。
delayedExecute
1
2
3
4
5
6
7
8
9
10
11
12
13
| private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
|
线程池已经关闭的话则拒绝任务
没关闭则将任务提交到队列
再次判断线程池是否已经关闭(),如果关闭的话继续判断是否应该在线程池关闭之后取消周期和非周期任务
如果线程池没关闭的话则调用ensurePrestart方法确保当前线程池中至少有一个线程
小结
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor使自身拥有了线程池的基本功能,不过由于调度任务的特殊性,需要重写execute和submit方法使提交的任务成为一次性执行的任务,同时实现了ScheduledExecutorService接口提供了特殊的任务调度功能。在执行任务调度时内部是将任务封装成一个ScheduledFutureTask对象,提交到最小堆队列中,然后基于线程池任务执行机制和最小堆的特性,每次线程从队列中获取到的都是最先执行的任务。
现在我们已经熟悉了ScheduledThreadPoolExecutor的基本执行流程,而ScheduledThreadPoolExecutor最为核心的点在于其内部的延迟队列。下面我们就来分析一下这个延迟队列的实现。
DelayedWorkQueue
在DelayedWorkQueue的注释中我们知道该队列是一个基于最小堆通过数组实现的阻塞队列,并且将任务添加到队列时都会将任务在数组中的索引记录到ScheduledFutureTask的heapIndex属性中,这样的话在执行注入contains和remove方法时可以将查找元素的时间复杂度可以从O(n)提升到O(logn)(这里有一个疑问点,DelayedWorkQueue的contains和remove方法都是直接通过数组索引定位元素的,时间复杂度不是O(1)吗?),前提是不要通过decorateTask方法来包装调度任务对象,因为在contains方法内部是只有ScheduledFutureTask类型的任务才会通过数组下标来定位,否则的话会遍历所有任务使得寻找任务的时间与总任务数成正比。下面我们来看一下这个队列内部的一些属性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
private static final int INITIAL_CAPACITY = 16;
private RunnableScheduledFuture<?>[] queue =
new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
private final ReentrantLock lock = new ReentrantLock();
private int size = 0;
private Thread leader = null;
private final Condition available = lock.newCondition();
|
DelayedWorkQueue是一个基于数组实现的最小堆数据结构,在上面的成员变量中有一个leader属性比较特殊,它是Leader-Follower线程模型的一种变体形式,当前正在队列的头部获取元素的线程就是一个Leader,当这个线程获取元素时,其它也尝试从头部获取元素的线程就会阻塞,就相当于Follower,然后当头部节点线程将节点拿出之后就会唤醒下一个Follower,这个Follower此刻就成为了新的Leader,循环往复,这样的好处就是永远只有一个头节点线程是处于定时等待状态,而其他的Follower线程都是处于永久等待状态,避免了多个线程处于定时等待再唤醒再等待的情况。
现在我们已经对DelayedWorkQueue的内部结构和线程如何从队列头部获取任务的机制有了简单的了解,接着我们看一下ThreadPoolExecutor中的线程是如何从队列中获取任务的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| private Runnable getTask() {
boolean timedOut = false;
for (;;) {
....省略部分代码
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
|
可以看到通过poll方法来获取带超时时间的任务,而阻塞的获取则是通过take方法来执行的。
我们继续回到ScheduledThreadPoolExecutor的delayedExecute方法中
1
2
3
4
5
6
7
8
9
10
11
12
13
| private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
|
看一看到任务入队是通过队列的add方法来实现的,那接下来我们就通过add和take方法来看一下DelayedWorkQueue内部的实现
add
1
2
3
| public boolean add(Runnable e) {
return offer(e);
}
|
内部是基于offer方法实现的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
if (i >= queue.length)
grow();
size = i + 1;
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
siftUp(i, e);
}
if (queue[0] == e) {
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
|
offer方法中最重要的点是非根节点入队时通过siftUp方法来为其找到合适的位置
siftUp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
|
siftUp方法的作用是从索引k位置开始递归为元素在堆中找到合适的位置,如果父节点的值比新加入节点的值大的话,由于最小堆的特性,需要将新节点与父节点替换然后递归直到找到比自身值小的父节点为止,整个过程中节点呈现的是上升趋势。整个siftUp方法的执行流程可以通过下图来表示:
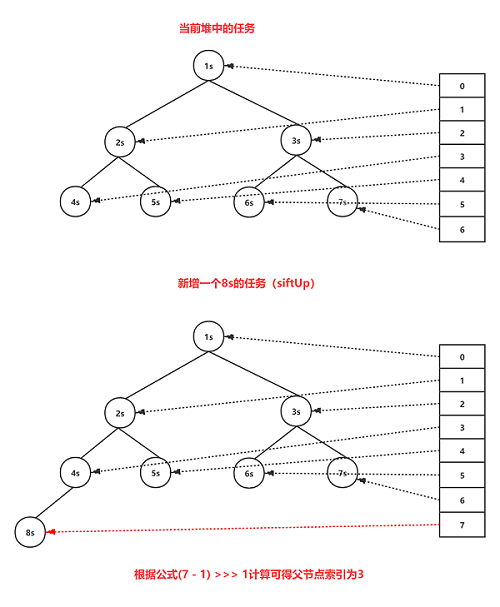
take
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return finishPoll(first);
first = null;
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
|
take方法中最重要的点是leader节点从队列头部取出任务时的finishPoll方法
finishPoll
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| private void siftDown(int k, RunnableScheduledFuture<?> key) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
RunnableScheduledFuture<?> c = queue[child];
int right = child + 1;
if (right < size && c.compareTo(queue[right]) > 0)
c = queue[child = right];
if (key.compareTo(c) <= 0)
break;
queue[k] = c;
setIndex(c, k);
k = child;
}
queue[k] = key;
setIndex(key, k);
}
|
siftDown方法的作用是从索引k位置开始往下最多递归能够拥有子节点的次数,只要找到索引k下的最小的那个子节点值比key还要大,说明key节点是能够成为索引k的子节点的,否则的话将索引k赋值为值最小的那个子节点,然后继续从该最小子节点的索引处往下递归直到将key放在合适的位置位置,整个过程中key节点呈现的是下降趋势。整个siftDown方法的执行流程可以通过下图来表示:

小结
DelayedWorkQueue使用数组实现最小堆来保存调度任务,数组中的第一个元素即为最先执行的任务,通过变种的Leader-Follower线程模型来控制线程对调度任务的获取,leader负责阻塞获取队列中最先执行的任务,当任务成功返回或者队列头部被具有更早执行任务替换时都会使当前leader失效(offer方法中失效)并发出一个信号使当前等待的线程中产生出下一个Follower。
总结
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor使自身拥有了线程池的基本属性,但是由于任务调度的特殊屏蔽了对maximumPoolSize的支持,仅仅使用corePoolSize作为固定大小线程池,并通过一个以数组实现的最小堆无界队列来保存那些被调度的任务,执行这些任务的线程只能是核心线程。